
In Machine Learning, the problem of classification involves predicting the categorical class label to which the query data point belongs. And the confusion matrix is a tabular representation of the classification model’s performance.

This tutorial will help you understand the confusion matrix and the various metrics that you can calculate from the confusion matrix.
We’ll start by explaining what classification is, the types of classification problems, and how to interpret the confusion matrix for a binary classification problem.
What is Classification ?

It is a Supervised Learning task where output is having defined labels(discrete value). For example in above figure, Output – Purchased has defined labels i.e. 0 or 1; 1 means the customer will purchase and 0 means that customer won’t purchase.
The goal here is to predict discrete values belonging to a particular class and evaluate them on the basis of accuracy. It can be either binary or multi-class classification. In binary classification, the model predicts either 0 or 1; yes or no but in the case of multi-class classification, the model predicts more than one class.
Example: Classifying groceries and vegetables bought from the market in to two classes.

Below is a Naive Bayes Classifier algorithms working. (At this point, dont think about the circles, just see how its been classifying. )

In essence, classification algorithms aim at answering the question,
“Given labeled training data points, what’s the class label of a previously unseen test, or query data point?”
A classification problem could be as simple as classifying a given image as that of a cat or a dog.
Or it could be as complex as examining brain scans to detect the presence or absence of tumors.
In binary classification, the class labels 1 and 0 are used.
Suppose you’re given a large dataset of student loans containing features such as the name of the university, tuition and employment details.
You’d like to predict whether or not a new student with a specific tuition fee and employment status will default on the student loan. Notice how you’re trying to answer the question “Will the student default on the loan?”—and the answer is either a ‘Yes’ or a ‘No’.
You might as well think of other examples, say, identifying spam emails – the answers in this case are ‘Spam’ or ‘Not Spam’.
In these examples,
- the answers ‘Yes’, ‘Spam’ indicate relevant classes, and in practice are encoded as class 1, and
- the answers ‘No’ and ‘Not Spam’ are encoded as class 0.
Using disease diagnosis as another example, if the problem is to detect the presence of a disease: label 1 indicates that the patient has the disease; and label 0 indicates the absence of the disease.
This classification problem where the data points belong to one of the two classes is called binary classification. And we’ll build on binary classification in this tutorial.
You can also have classification problems where you have more than two classes, called multiclass classification.
For instance, classifying an email as ‘Spam’ or ‘Not Spam’ is a binary classification problem, whereas, categorizing emails as ‘School’, ‘Work’ or ‘Personal’ is a multiclass classification problem.
Now that you’ve gained an understanding of the types of classification, let’s proceed to understand the confusion matrix.
We will see the explanation of multiclass confusion matrix towards the end. First we see the working of binary class confusion matrix .
General Structure of the Confusion Matrix
The general structure of the confusion matrix for binary classification is shown below

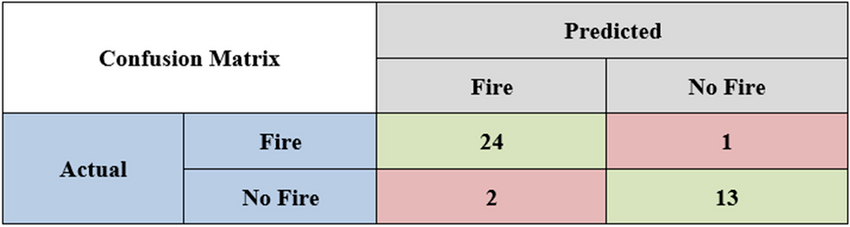
It provides accurate insight into how correctly the model has classified the classes depending upon the data fed or how the classes are misclassified.
